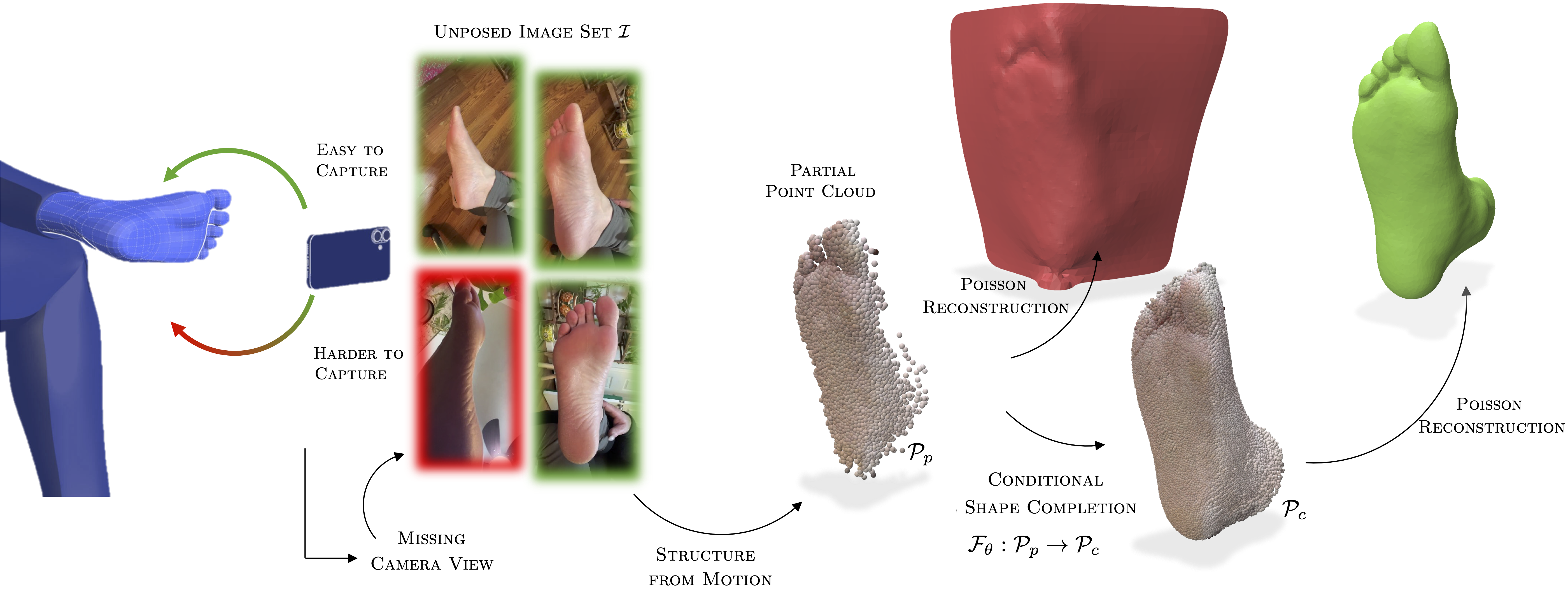
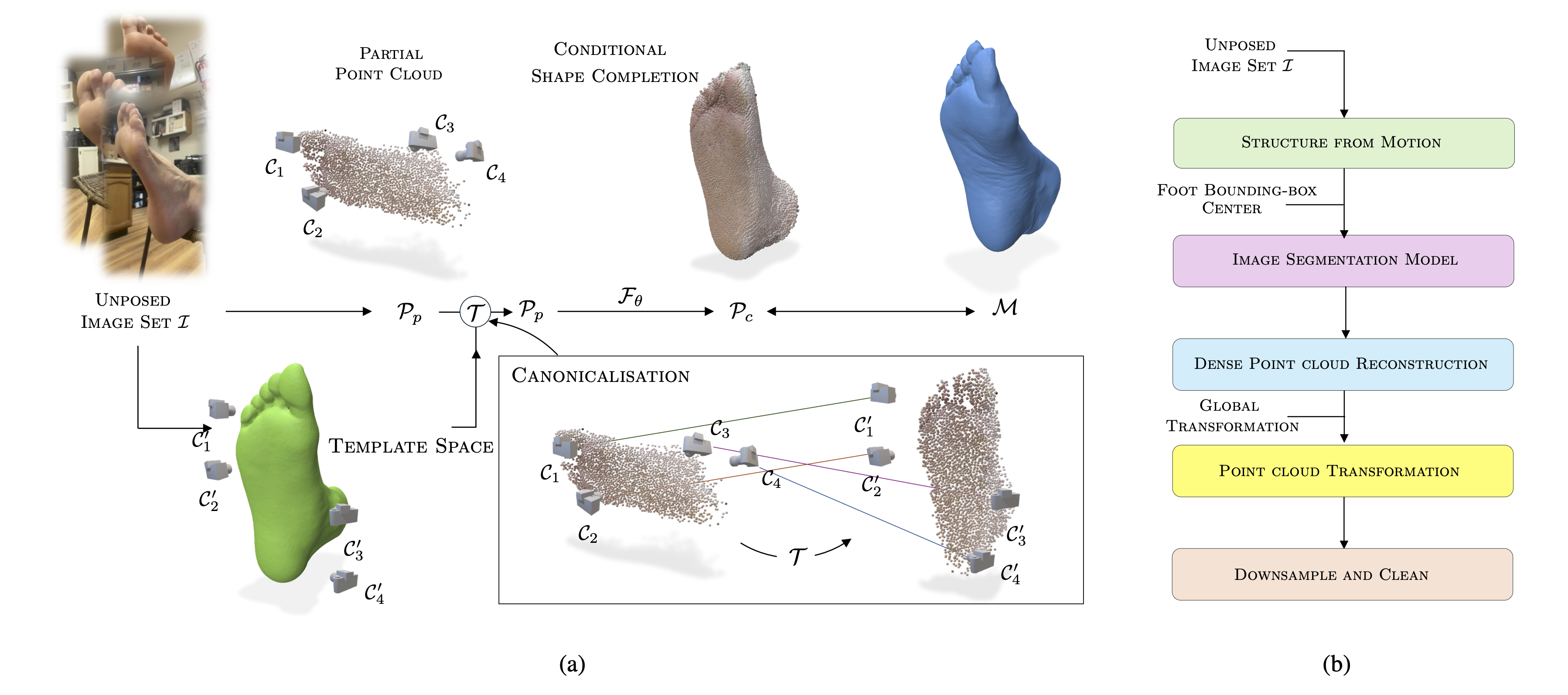
Accurate 3D foot reconstruction is crucial for personalized orthotics, digital healthcare, and virtual try-ons. However, existing methods struggle with incomplete scans and anatomical variations, particularly in self-scanning scenarios where user mobility is limited, making it difficult to capture areas like the arch and heel. We propose a novel end-to-end pipeline that enhances Structure-from-Motion (SfM) reconstruction by integrating a transformer-based geometry completion network trained on synthetically augmented point clouds. This network encodes anatomical priors to improve reconstruction accuracy, while a separate viewpoint prediction module provides SE(3) canonicalization, reducing ambiguities in scan alignment. Our approach achieves state-of-the-art performance on reconstruction metrics while preserving clinically validated anatomical fidelity. By combining synthetic training data with learned geometric priors, we enable robust foot reconstruction under unconstrained capture conditions, unlocking new opportunities for mobile-based 3D scanning in healthcare and retail.